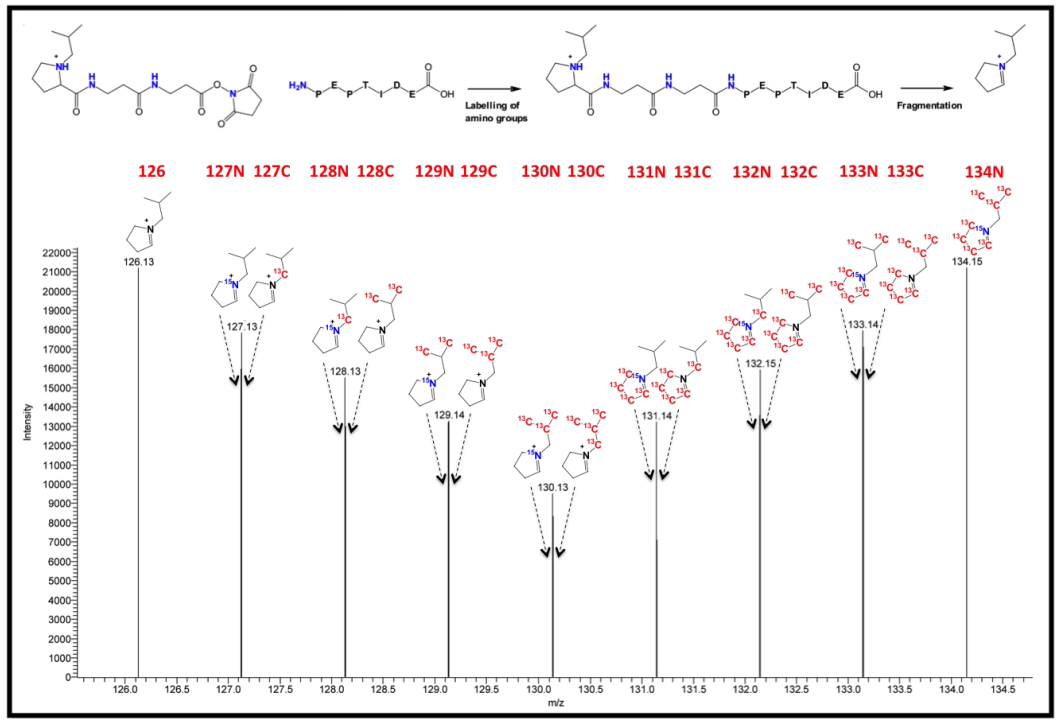
O prefeito Clébio Pavone enviou à Câmara Municipal de Quixeramobim um projeto de lei do executivo que cria o “Cartão do Bem”. A proposta foi o principal assunto desta quarta-feira, 20/11, quando ocorreu a sessão ordinária na casa legislativa.
Os vereadores rejeitaram a urgência simples e acataram o projeto que segue agora para a Comissão de Legislação, Justiça e Redação, que tem como presidente o vereador Everardo Júnior. Em conversa com a reportagem, o presidente Idelbrando Rocha revelou que, possivelmente, o projeto deve retornar ao plenário, desta vez com o parecer da comissão, para votação ainda este ano. É intenção de Pavone lançá-lo em dezembro.
O ‘Cartão do Bem’ prevê o pagamento de R$ 60,00, inicialmente, a 500 pessoas em situação de extrema pobreza no município. O pagamento, conforme revelou o prefeito Clébio Pavone, em entrevista ao Programa SerTão Conta Mais, da rádio Campo Maior AM 840, antes da votação, será proveniente de recursos próprios do município, administrado pela Secretaria de Assistência e Desenvolvimento Social (SADS), com base nas informações extraídas do Cadastro Único do Bolsa Família, programa do Governo Federal.
O assunto foi alvo de constante debate. O prefeito se dirigiu ao Legislativo, ao lado de secretários, incluindo Edson Facó, da Administração e Finanças, para acompanhar de perto a votação.
Como votaram
Seis vereadores foram favoráveis ao regime de urgência simples do projeto, ou seja, onde seriam deixadas de lado as formalidades para que se possa ir direto ao ponto: A apreciação do projeto na mesma sessão. Foram eles:
Antônio do Couto (Cego)
Antônio Filho
Edson Nogueira
Everardo Júnior
Fernando Antônio
Roberlan Saldanha
Já oito parlamentares foram contrários ao regime, desta forma, o projeto segue para a Comissão de Legislação, Justiça e Redação:
Claudinha Borges
Célio Neto
Cristina Pimenta
Evando Cosmo
Francisco José, o Kim
François Saldanha
Terezinha Pimentel
José Wilson Paulino
Era necessária maioria absoluta favorável para que a urgência fosse aprovada e ainda na sessão desta quarta-feira submetida a votação. O presidente não vota.
Quais os critérios de inclusão no programa
O projeto ainda pode sofrer alterações na Comissão. No entanto, o texto atualmente apresentado pelo prefeito, determina que o ‘Cartão do Bem’ tem como critérios para concessão do benefício os seguintes requisitos, resumidamente:
1 – Famílias com renda per capita (por pessoa) igual ou inferior a R$ 89,00.
2 – Que não estejam inseridas em mais de 1 programa de transferência de renda.
3 – Que possuem 2 membros, desde que um deles seja criança ou adolescente até 14 anos ou pessoa em situação de rua.
4 – Que estejam, no mínimo, inseridas há 24 meses no Cadastro Único.
5 – Que residem em condições de moraria precária (difícil acesso, sem água encanada, sem saneamento ou seja de taipa), salve pessoa em situação de rua.
6 – Pessoa em situação de rua com família unipessoal ou com membros.
Critérios de permanência no programa
1 – Participar regularmente de serviços, programas e projetos da SADS.
2 – Moradia livre de foco do Aedes Aegypti.
3 – Manter atualizado cadastro no CRAS.
4 – Manter vacinação e puericultura atualizados.
5 – Frequência escolar de crianças igual ou superior a 85% e adolescentes igual ou superior a 75%.
Além disso o projeto prevê ainda os critérios de desempate e evidentemente, de exclusão (neste caso, o não cumprimento dos demais).
Compromisso de campanha
Uma das principais propostas de Clébio Pavone durante a campanha eleitoral foi a criação de um ‘Bolsa Família Municipal’. A proposta chegou a receber inúmeras críticas de opositores, que o criticavam por não cumpri-lá. Superado os atrasos na folha de pagamento, Pavone joga para a Câmara Municipal, composta em sua maioria por opositores, a responsabilidade de aprovar a proposta, anteriormente criticada por não existir.
Traduzindo, agora está nas mãos do Legislativo a autorização para criação do ‘Cartão do Bem’.